
Creating a Machine Learning Cloud stack to play rock paper scissors
Hi! I’m Alejandro Barón, a Computer Engineer & Statistician. I like working with Machine Learning in all stages of the process; concepting the algorithm, training and testing models and then deploying it (where’s the fun if you are stuck with your ML model in a lab!). In fact, I always wanted a way to showcase my projects, that’s why I started this blog, but this stack I’ve made makes it so much richer since the user can interact with the project itself!
I created this project as a template/baseline project to have a fully functional stack for any Machine Learning project. However, since the main purpose of this app was to create my own complete baseline infrastructure for other projects, I started with a very simple model WARNING: the bot itself is still in an early stage and learning, so don’t expect a Rock Paper Scissors “terminator”.
You can play here (since I’m using a free plan, it shuts down if no user activity was detected in the last 30 mins, so it may take 20 seconds or so to boot): https://alexbaronrps.herokuapp.com/.
Code is available on my github: https://github.com/AlejandroBaron/rps-cloud. Feel free to use it as long as you give me some credit ;)
The idea is to keep increasing the project to include other tasks. Right now, it covers:
- Databases
- Data visualization Model Monitoring
- Model (online) training
- Hosting the model and making it learn from user usage
Anyway, let’s dive into the project:
The algorithm: How does the bot make predictions?
At first, I was planning to use a Machine Learning model, something like an LSTM that recognized patterns within the user move history. In the meantime, I discovered The RPSContest.com website that offers much simpler approaches, some of them based on plain heuristics. Some approaches (from which I took inspiration and made my own version) like the one I’m using here claim to have a 70% winrate https://towardsdatascience.com/how-to-win-over-70-matches-in-rock-paper-scissors-3e17e67e0dab.
One of the things I’ve learnt during these years working with ML projects is that simpler is better. However, I also wanted to work with data, that’s why I went with a statistical yet simpler approach: Markov Chains
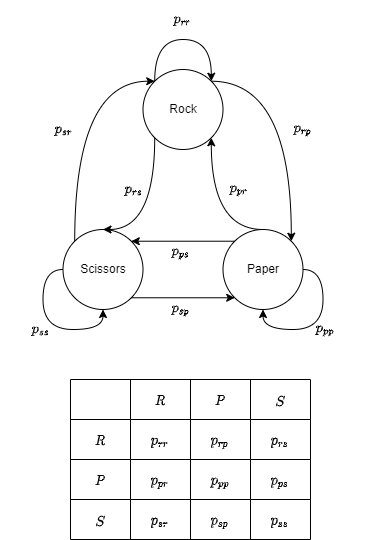
This Markov chain represents three possible states: We played Rock, Paper or Scissors last turn. Each path in the graph is associated with a transition probability, like $p_{rp}$ which represents the probability of, given that we played Rock last turn, playing paper next turn. All the possible matrices are portrayed in the transition matrix under the graph, which is a fantastic probability structure with many advantages that I won’t cover here because this would become huge.
If we were absolutely random, we would have that:
\[\forall i, j \in \{r,p,s\}, \: p_{i,j} = 1/3 \:\:\]Which is a fancy way of saying that the next move we chose would be completely random and non dependant of the past move.
However, we might assume that it is not. That there is one case where the previous statement does not hold. That would mean that there is a pattern and we could use that to exploit the Rock Paper Scissors game. In fact, we could assume that the next move depends not only on the previous move but on the last two moves, in which case we’d have a two stages Markov Chain, which we could represent like follows:
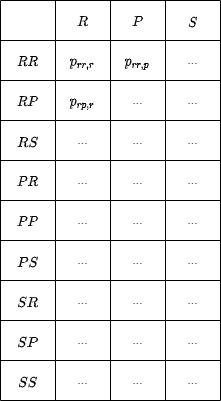
To be fair, this matrix is not a proper Markov Transition Matrix . All possible states should be included, and the destination states should be the next user history (from RR we would go to RR, RP, RS). However, some probabilities would be zero like $p_{pp,ss}$ (you can’t have SS as your move history if your last move was paper) and the matrix would be huge. This is, let’s call it, a summarized version.
So, the idea is to estimate the $p_{i,j}$ for the table above. How do we do it? As simple as it can get!
\[\hat{p}_{i,j} : \frac{\text{Number of times a player went from i to j} + 1}{\text{Number of times a player went from i to another state} + V}\]That $\frac{…+1}{…+V}$ with $V=3$ represents the Laplace correction, which gives every state an initial and equal probability. This concept is commonly used in text classification and Naive Bayes classifiers, pretty useful.
The transition matrix will get updated every time someone plays, making it learn on the go!
Making things interesting:
What about if the real influence is three moves back? Or four? Do not worry! The bot I implemented presents every time you play a different version of itself; any time you load the page, you will be playing agains a slightly different version depending on a random selection of the depth parameter. This will allow to collect some user and performance statistics and choose the best depth parameter in the future.
Also, to ease the cold start problem, the bot makes a weighted prediction using a past weight parameter. All the previous players games are stored in one matrix, and the current user game is stored in a unique one. The initial weight is 50-50%, but this weight decays over time in favour of the unique matrix, so the most recent user plays have a heavier weight, up to a minimum of 25%.
To be honest I don’t know if this is the most efficient parameter setting, but we’ll revisit the project once some games have been played.
Also, in my early tests, I found out that I was able to be more chaotic on a touchscreen than using a mouse. I’ll be tracking the user platform too to see if there is any differences.
The Tech stack
I’m using the following tech/libraries to deploy the solution
-
Interface: PyWebIO, allows you to create simple webpages in a script fashion, way easier than setting up a Flask/Django based webpage. However, if you need more complex UI, this might fall short
-
Database: I’m uisng a PostgreSQL database to store the transition matrices and the usage statistics/monitoring. I’m storing each single round played for future use.
-
Host: Heroku will be the cloud solution used to host both the web server and the database
-
Terraform: To deploy the project, I’ll be using Terraform, an Infrastructure as Code (IaaC) approach that eases the reliance on each cloud provider
Due to the modular design, any of the points above can be changed without much trouble (for instance, if I wanted to use AWS to host the container for the website host, I could just change that in the terraform files and switch the solution), or maybe re-use this code for a different project in which I would need to change the interface but keep the rest of the stack the same! Also, I have a local version that uses docker-compose, in case you want to do some testing.
Any questions or ideas you might have, feel free to ask or share!
Future plans
From what I’ve seen, the user behaviour is very different depending on the platform, so maybe a custom model will for each platform. I’ve tried to be transparent and show the winrates as they are, even if they are not that great. Right now the bot is able to snatch around 5% winrate over the expected winrate if we actually random (50%)
Also, I plan to try other cloud providers and maybe introduce some automation tasks into the stack, like an MLFlow server, or Jenkins/Airflow for future projects.